Evaluating LLMs for Regulated Industries
I've spent the last several months helping financial services companies get large language models into production. Every one of these engagements starts in roughly the same place: a team has built a compelling prototype, leadership is excited, and then someone from compliance asks a question that stops the room cold. "How do we know this will behave correctly when it matters?"
That question is harder to answer than it sounds. In most software, you write tests against deterministic behavior. Input A produces output B. LLMs don't work that way. The same prompt can produce meaningfully different outputs across runs, model versions, and context windows. For a consumer app, that variability is a feature. For a platform handling financial transactions, regulatory filings, or investment recommendations, it's a risk that needs to be measured, bounded, and continuously monitored.
The companies getting this right are building evaluation infrastructure that looks very different from traditional QA. Here's what I've seen work.
Domain-specific test suites are the foundation
Generic benchmarks tell you almost nothing useful about how an LLM will perform in your specific domain. MMLU scores and HumanEval results are interesting for comparing models at a high level, but they won't tell you whether a model can correctly interpret ISDA master agreement clauses or flag inconsistencies in SEC filing language.
The first real investment is building domain-specific test suites. These need to be constructed with your subject matter experts, not just your engineers. In financial services, that means getting portfolio managers, compliance officers, risk analysts, and legal counsel to help define what "correct" looks like for your use cases. This is slow, unglamorous work. It's also the most important work you'll do in the entire evaluation process.
A good domain test suite covers several dimensions:
- Factual accuracy: Does the model get domain-specific facts right? Can it correctly calculate a debt service coverage ratio or identify the relevant regulatory framework for a given transaction type?
- Boundary behavior: How does the model handle edge cases, ambiguous inputs, and scenarios where the correct answer is "I don't know"? In regulated environments, a confident wrong answer is far more dangerous than no answer at all.
- Consistency: Given the same input across multiple runs, how much does the output vary? Where variation exists, is it within acceptable bounds?
- Regulatory alignment: Does the model's output comply with the specific regulations governing your business? This is where compliance and legal expertise become essential.
These test suites aren't something you build once. They evolve with your use cases, your regulatory environment, and the models themselves. Version them. Review them quarterly. Treat them with the same rigor as your production code.
The model promotion pipeline
In traditional software, promoting a build from staging to production is well understood. You run your test suite, check coverage metrics, get approval, and deploy. LLM promotion is fundamentally more complex because the artifact you're evaluating (a model, a fine-tune, a prompt configuration) can exhibit different behavior depending on load, context length, and the distribution of real-world inputs.
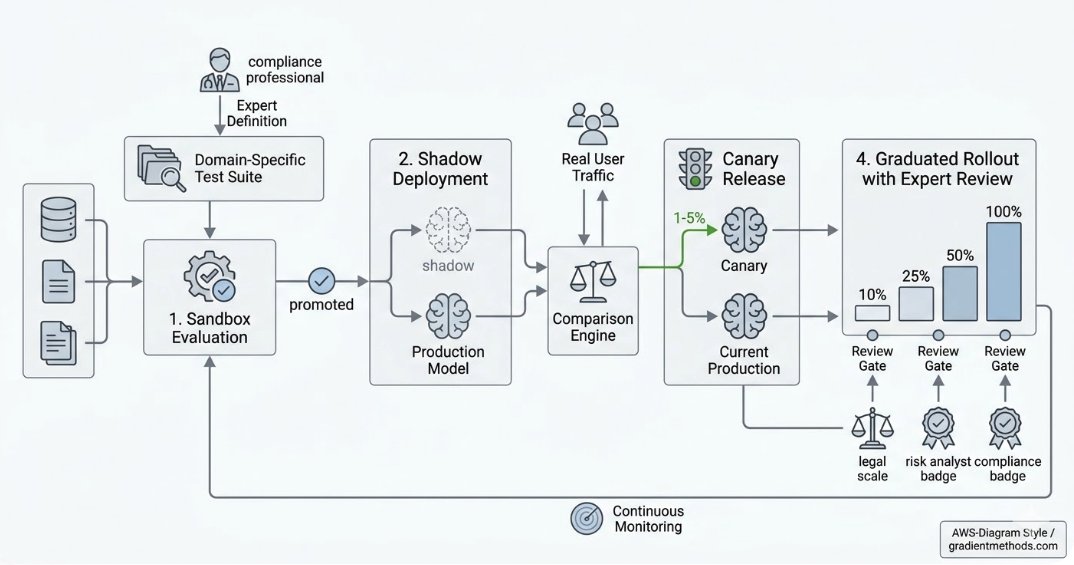
The promotion pipeline I recommend for regulated environments has four stages:
1. Sandbox evaluation
Run the candidate model against your full domain test suite in isolation. This is your first gate, and it should be automated. If a model can't pass your baseline accuracy, consistency, and safety thresholds here, it doesn't move forward. Track results over time so you can see trends across model versions.
2. Shadow deployment
Deploy the candidate model alongside your current production model. Route real traffic to both, but only serve responses from the existing model. Compare outputs. This stage catches problems that synthetic test suites miss, because real user inputs are messier and more varied than anything your test suite covers. Shadow deployments also give you latency and throughput data under realistic conditions.
3. Canary release
Route a small percentage of real traffic (typically 1-5%) to the candidate model and serve its responses to actual users. Monitor closely. This is where you discover failure modes that only emerge at scale or with certain user populations. In financial services, I recommend starting with internal users or a trusted client cohort before opening the canary to your broader user base. Define rollback criteria in advance: if error rates exceed a threshold, if compliance flags spike, or if latency degrades, the canary terminates automatically.
4. Graduated rollout with expert review
Increase traffic gradually (10%, 25%, 50%, 100%) with human review gates at each step. For regulated use cases, this means having domain experts review a statistically significant sample of the candidate model's production outputs at each stage. Automated metrics catch most issues, but some failure modes (subtle mischaracterizations of risk, technically-correct-but-misleading summaries) require human judgment to detect.
Expert stakeholders in the loop
This is where most engineering teams underinvest. You can build a technically excellent evaluation pipeline, but if your compliance team doesn't trust it, the model never ships. And they shouldn't trust it on faith alone.
The organizations I've seen succeed at this build expert review into the process from day one. Compliance officers help define test cases. Risk analysts review shadow deployment comparisons. Legal counsel signs off on the evaluation criteria for regulatory alignment. These aren't after-the-fact approvals. They're integrated into the pipeline.
Practically, this means building review interfaces that non-engineers can use. A compliance officer doesn't want to read JSON output diffs. They want to see the model's response next to the expected response, with differences highlighted, and a clear way to flag issues. Investing in this tooling pays for itself many times over, because it turns expert review from a bottleneck into a scalable process.
I also recommend establishing an evaluation committee that includes engineering, compliance, risk, and business stakeholders. This group owns the promotion criteria and meets at each stage gate. It sounds bureaucratic, and in a startup context it might feel heavy. But in regulated industries, having a clear decision-making process with documented sign-offs is table stakes. Regulators will ask how you validated the model. "We ran some tests and it looked good" won't cut it.
Continuous monitoring after deployment
Promotion to production is a milestone, not a finish line. LLM behavior can drift as input distributions change, as upstream dependencies evolve, or as the model provider makes changes on their end. (If you're using a hosted model API, you don't always get advance notice of version bumps.)
Post-deployment monitoring should include:
- Output quality sampling: Regularly pull random samples of production outputs and run them through automated evaluation and human review.
- Regression testing: Continuously run your domain test suite against the production model. Catch degradation early.
- Feedback loops: Build mechanisms for end users and internal stakeholders to flag problematic outputs. Route these flags into your test suite to prevent recurrence.
- Audit trails: Log inputs, outputs, model versions, and configuration for every inference. In regulated environments, this is typically a compliance requirement, but it's also invaluable for debugging and evaluation refinement.
The organizational challenge
The hardest part of LLM evaluation in regulated industries isn't technical. It's organizational. Engineering teams want to move fast. Compliance teams want to move carefully. Business stakeholders want results yesterday. Building an evaluation pipeline that satisfies all three requires genuine cross-functional collaboration, and that collaboration needs executive sponsorship to work.
The companies I work with that do this well typically have someone (often a fractional CTO or a senior engineering leader) who can translate between these constituencies. Someone who can explain to the compliance team why shadow deployments provide stronger safety guarantees than a manual review process, and can explain to the engineering team why a four-stage promotion pipeline with expert review gates is worth the additional cycle time.
LLMs are going to transform financial services. The organizations that figure out rigorous, auditable, expert-informed evaluation pipelines will be the ones that capture that value. Everyone else will be stuck in prototype limbo, unable to bridge the gap between "this demo is impressive" and "this is in production."
If you're working through this problem, I'd enjoy comparing notes. This is exactly the kind of challenge we take on at Gradient Methods.